Overview | Argoverse 2
Argoverse 2 is a collection of open-source autonomous driving data and high-definition (HD) maps from six U.S. cities: Austin, Detroit, Miami, Pittsburgh, Palo Alto, and Washington, D.C. This release builds upon the initial launch of Argoverse (“Argoverse 1”), which was among the first data releases of its kind to include HD maps for machine learning and computer vision research.
Argoverse 2 includes four open-source datasets:
- Argoverse 2 Sensor Dataset: contains 1,000 3D annotated scenarios with lidar, stereo imagery, and ring camera imagery. This dataset improves upon the Argoverse 1 3D Tracking dataset.
- Argoverse 2 Motion Forecasting Dataset: contains 250,000 scenarios with trajectory data for many object types. This dataset improves upon the Argoverse 1 Motion Forecasting Dataset.
- Argoverse 2 Lidar Dataset: contains 20,000 unannotated lidar sequences.
- Argoverse 2 Map Change Dataset: contains 1,000 scenarios, 200 of which depict real-world HD map changes
Argoverse 2 datasets share a common HD map format that is richer than the HD maps in Argoverse 1. Argoverse 2 datasets also share a common API, which allows users to easily access and visualize the data and maps.
Terms of Use
We created Argoverse to support advancements in 3D tracking, motion forecasting, and other perception tasks for self-driving vehicles. We offer it free of charge under a creative commons share-alike license. Please visit our Terms of Use for details on licenses and all applicable terms and conditions.
Citation
The Argoverse 2 datasets are described in our publications, Argoverse 2 and Trust, but Verify, in the NeurIPS 2021 dataset track. When referencing these datasets or any of the materials we provide, please use the following citations
@INPROCEEDINGS { Argoverse2,
author = {Benjamin Wilson and William Qi and Tanmay Agarwal and John Lambert and Jagjeet Singh and Siddhesh Khandelwal and Bowen Pan and Ratnesh Kumar and Andrew Hartnett and Jhony Kaesemodel Pontes and Deva Ramanan and Peter Carr and James Hays},
title = {Argoverse 2: Next Generation Datasets for Self-driving Perception and Forecasting},
booktitle = {Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks (NeurIPS Datasets and Benchmarks 2021)},
year = {2021}
}
@INPROCEEDINGS { TrustButVerify,
author = {John Lambert and James Hays},
title = {Trust, but Verify: Cross-Modality Fusion for HD Map Change Detection},
booktitle = {Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks (NeurIPS Datasets and Benchmarks 2021)},
year = {2021}
}
Where was the data collected?
The data in Argoverse 2 comes from six U.S. cities with complex, unique driving environments: Miami, Austin, Washington DC, Pittsburgh, Palo Alto, and Detroit. We include recorded logs of sensor data, or "scenarios," across different seasons, weather conditions, and times of day.
How was the data collected?
We collected all of our data using a fleet of identical Ford Fusion Hybrids, fully integrated with Argo AI self-driving technology. We include data from two lidar sensors, seven ring cameras, and two front-facing stereo cameras. All sensors are roof-mounted:
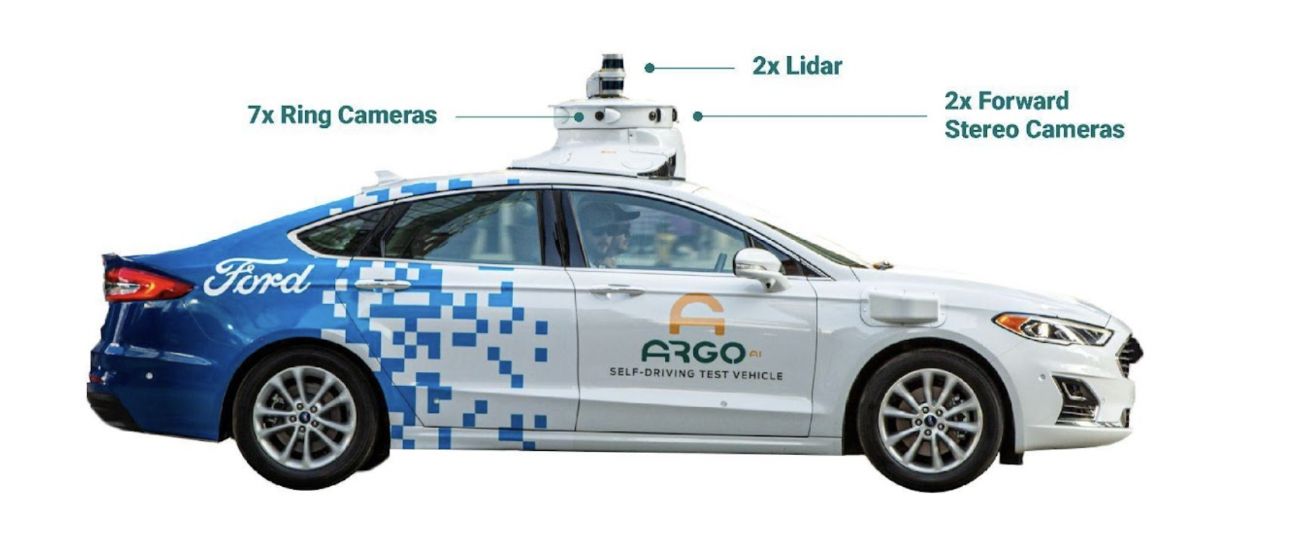
Lidar
- Two roof-mounted VLP-32C lidar sensors (64 beams total)
- Overlapping 40° vertical field of view
- Range of 200 m
- On average, our lidar sensors produce a point cloud with ~ 107,000 points at 10 Hz
Localization
We use a city-specific coordinate system for vehicle localization. We include 6-DOF localization for each timestamp, from a combination of GPS-based and sensor-based localization methods.
Cameras
- Seven high-resolution ring cameras (2048 width x 1550 height) recording at 20 Hz with a combined 360° field of view. Unlike Argoverse 1, the camera and lidar are synchronized. The camera images are captured as one of the two lidars sweep past its field of view. The front center camera is portrait aspect ratio (1550 width x 2048 height) to improve the vertical field of view.
- Two front-view facing stereo cameras (2048 x 1550) sampled at 20 Hz
Calibration
Sensor measurements for each driving session are stored in “scenarios.” For each scenario, we provide intrinsic and extrinsic calibration data for the lidar and all nine cameras.
Argoverse 2 Maps
Each scenario is paired with a local map. Our HD maps contain rich geometric and semantic metadata for better 3D scene understanding.
Vector Map: Lane-Level Geometry
Our semantic vector map contains 3D lane-level details, such as lane boundaries, lane marking types, traffic direction, crosswalks, driveable area polygons, and intersection annotations. These map attributes are powerful priors for perception and forecasting. For example, vehicle heading tends to follow lane direction, drivers are more likely to make lane changes where there are dashed lane boundaries, and pedestrians are more likely to cross the street at designated crosswalks.
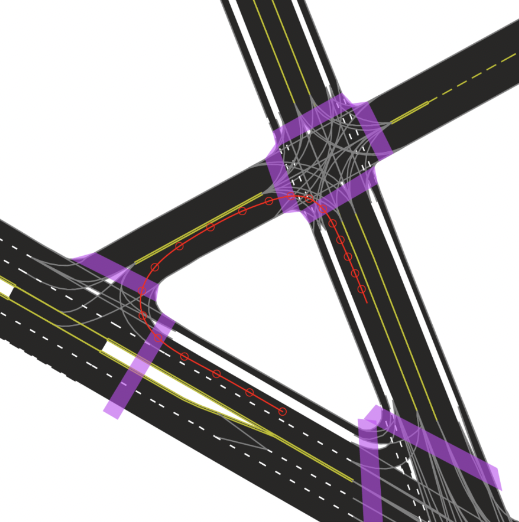
An example of an HD map for an Argoverse 2 scenario.
This map format is shared by the Sensor, Lidar, Motion Forecasting, and Map Change datasets. This figure shows a rendering of the “vector” map with polygons and lines defining lanes, lane boundaries (dashed white, dashed yellow, double yellow, etc), and crosswalks (purple). Implicit lane boundaries, such as the corridor a vehicle is likely to follow through an intersection, are shown in gray. The path of the ego-vehicle is shown in red.
Raster Map: Ground Height
To support the Sensor and Map Change datasets, our maps include real-valued ground height at thirty centimeter resolution. With these map attributes, it is easy to filter out ground lidar returns (e.g. for object detection) or to keep only ground lidar returns (e.g. for building a bird’s-eye view rendering).

Ground height samples for an Argoverse 2 scenario.
Ground height samples are visualized as blue points. Lidar samples are shown with color projected from ring camera imagery.
Argoverse 2 API
Our API enables users to access, visualize, and experiment with Argoverse 2 sensor, trajectory, and map data. We provide this API in Python and encourage community submissions.
Visit the Argoverse 2 API.
Argoverse 2 Sensor Dataset
A dataset to train and validate 3D scene perception algorithms
The Argoverse 2 Sensor Dataset is a collection of 1,000 scenarios with 3D object tracking annotations. Each sequence in our training and validation sets includes annotations for all objects within five meters of the “drivable area” — the area in which it is possible for a vehicle to drive. The HD map for each scenario specifies the driveable area.
What makes this dataset stand out?
With data from six U.S. cities, this dataset includes 30 object classes and complex urban scenarios. It also includes many moving objects and objects at range.
Scenario duration:
15 seconds
Total number of scenarios:
1000
Average number of cuboids per frame:
75
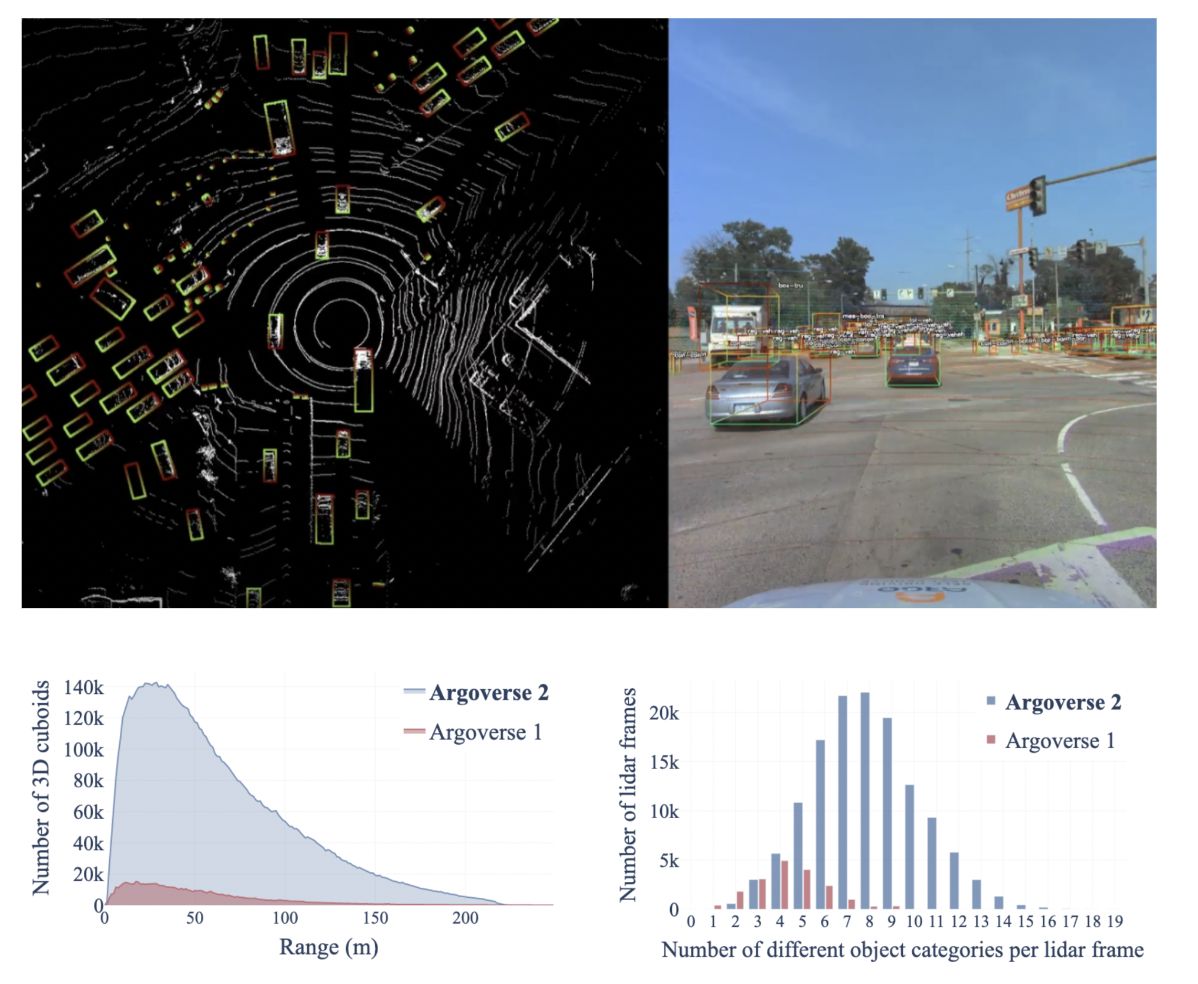
Data Annotation
The sensor dataset contains amodal 3D bounding cuboids on all objects of interest on or near the drivable area. By “amodal” we mean that the 3D extent of each cuboid represents the spatial extent of the object in 3D space — and not simply the extent of observed pixels or observed lidar returns, which is smaller for occluded objects and ambiguous for objects seen from only one face.
Our amodal annotations are automatically generated by fitting cuboids to each object’s lidar returns observed throughout an entire tracking sequence. If the full spatial extent of an object is ambiguous in one frame, information from previous or later frames can be used to constrain the shape. The size of amodal cuboids is fixed over time. A few objects in the dataset dynamically change size (e.g. a car opening a door) and cause imperfect amodal cuboid fit.
To create amodal cuboids, we identify the points that belong to each object at every timestep. This information, as well as the orientation of each object, comes from human annotators.
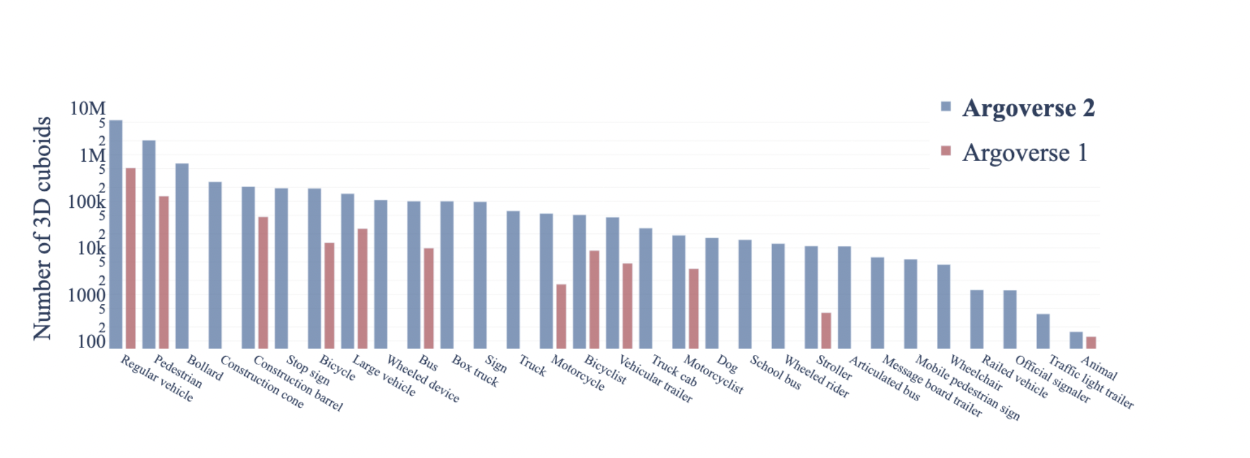
We provide ground truth labels for 30 object classes. The distribution of these object classes across all of the annotated objects in the Argoverse 2 Sensor Dataset looks like this:
To download, visit our downloads section.
Argoverse 2 Lidar Dataset
One of the largest lidar datasets in the autonomous vehicle industry
The Argoverse 2 Lidar Dataset is a collection of 20,000 scenarios with lidar sensor data, HD maps, and ego-vehicle pose. It does not include imagery or 3D annotations. The dataset is designed to support research into self-supervised learning in the lidar domain, as well as point cloud forecasting.
We’ve divided the dataset into train, validation, and test sets of 16,000, 2,000, and 2,000 scenarios. This supports a point cloud forecasting task in which the future frames of the test set serve as the ground truth. Nonetheless, we encourage the community to use the dataset broadly for other tasks, such as self-supervised learning and map automation.
All Argoverse datasets contain lidar data from two out-of-phase 32 beam sensors rotating at 10 Hz. While this can be aggregated into 64 beam frames at 10 Hz, it is also reasonable to think of this as 32 beam frames at 20 Hz. Furthermore, all Argoverse datasets contain raw lidar returns with per-point timestamps, so the data does not need to be interpreted in quantized frames.
What makes this dataset stand out?
The Lidar Dataset contains 6 million lidar frames, one of the largest open-source collections in the autonomous driving industry to date. Those frames are sampled at high temporal resolution to support learning about scene dynamics.
Scenario duration:
30 seconds
Total number of scenarios:
20,000
Framerate:
10 Hz


Visualizations of Lidar Dataset scenarios. For these bird's eye view visualizations, lidar returns from all 300 frames have been accumulated in the city coordinate system. The veiwpoint follows the motion of the ego-vehicle (red circle). Lane markings and crosswalks are shown from the HD map.
To download, visit our downloads section.
Argoverse 2 Motion Forecasting Dataset
A dataset to train and validate motion forecasting models
The Argoverse 2 Motion Forecasting Dataset is a curated collection of 250,000 scenarios for training and validation. Each scenario is 11 seconds long and contains the 2D, birds-eye-view centroid and heading of each tracked object sampled at 10 Hz.
To curate this collection, we sifted through thousands of hours of driving data from our fleet of self-driving test vehicles to find the most challenging segments. We place special emphasis on kinematically and socially unusual behavior, especially when exhibited by actors relevant to the ego-vehicle’s decision-making process. Some examples of interactions captured within our dataset include: buses navigating through multi-lane intersections, vehicles yielding to pedestrians at crosswalks, and cyclists sharing dense city streets.
What makes this dataset stand out?
Spanning 2,000+ km over six geographically diverse cities, Argoverse 2 covers a large geographic area. Argoverse 2 also contains a large object taxonomy with 10 non-overlapping classes that encompass a broad range of actors, both static and dynamic. In comparison to the Argoverse 1 Motion Forecasting Dataset, the scenarios in this dataset are approximately twice as long and more diverse.
Together, these changes incentivize methods that perform well on extended forecast horizons, handle multiple types of dynamic objects, and ensure safety in long tail scenarios.
Scenario duration:
11 seconds
Total number of scenarios:
250,000
Total time:
763 hours
Unique roadways:
2110 km
Unique object classes:
10
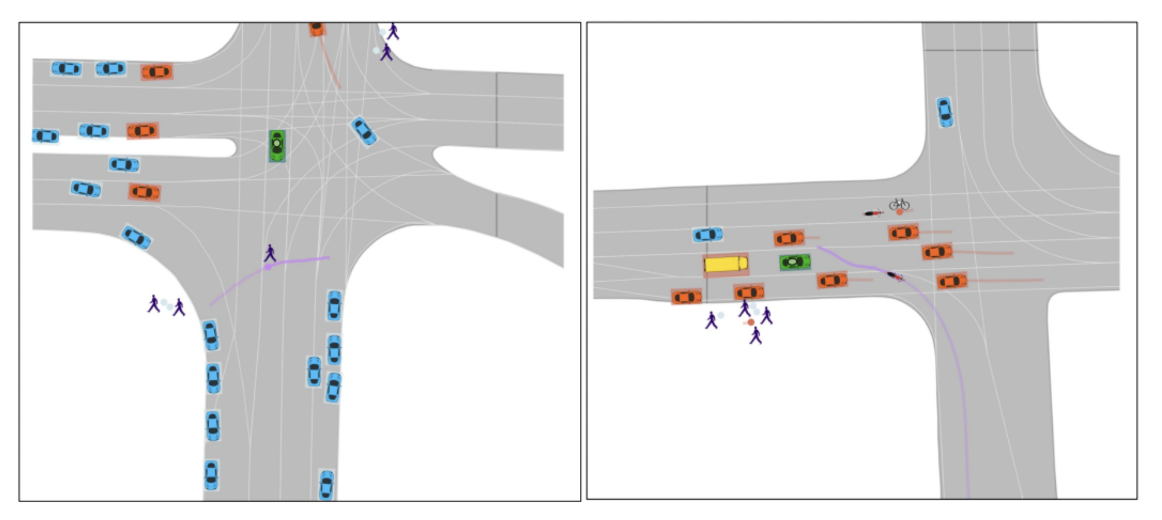
Two scenarios from the Argoverse 2 Motion Forecasting Dataset. The scenarios include several object types (i.e. Bus, Vehicle, Motorcycle). The ego-vehicle is indicated in green, the focal agent is indicated in purple, and other possible forecasting targets are indicated in orange. Additional tracks are shown in blue. Left shows a pedestrian crossing in front of the ego-vehicle, while Right depicts a motorcyclist weaving through traffic.
To download, visit our downloads section.
Argoverse 2 Map Change Dataset
A first-of-its-kind map change dataset
The Argoverse 2 Map Change Dataset is a collection of 1,000 scenarios with ring camera imagery, lidar, and HD maps. Two hundred of the scenarios include changes in the real-world environment that are not yet reflected in the HD map, such as new crosswalks or repainted lanes. By sharing a map dataset that labels the instances in which there are discrepancies with sensor data, we encourage the development of novel methods for detecting out-of-date map regions.
The Map Change Dataset does not include 3D object annotations (which is a point of differentiation from the Argoverse 2 Sensor Dataset). Instead, it includes temporal annotations that indicate whether there is a map change within 30 meters of the autonomous vehicle at a particular timestamp. Additionally, the scenarios tend to be longer than the scenarios in the Sensor Dataset. To avoid making the dataset excessively large, the bitrate of the imagery is reduced.
Scenario duration:
~45 seconds
Total number of scenarios:
1,000
Number of map changes encountered:
200

Frames from eight scenarios in the Argoverse 2 Map Change Dataset. The left frame in each pair depicts a situation in which there is a discrepancy between the HD map and sensor data.
Data Splits
The Map Change Dataset is uniquely designed so that the train and validation sets do not contain map changes. We preserve scenarios with map changes for the test set so that we can more reliably evaluate map change detection algorithms, given the rarity of map changes. The 200 test scenarios contain thousands of frames with and without map changes, so the test set is roughly balanced.
While the train and validation sets are one class (meaning there are no examples of the maps and sensor data misaligning), it is possible to create mismatches by synthetically perturbing HD maps. For example, users can delete or add elements (such as crosswalks or lanes), or perturb attributes (such as lane locations or lane marking types). Alternatively, “bottom up” map change detection algorithms that detect lane markings explicitly require aligned sensor and map data for training. The accurately mapped training and validation data of the Map Change Dataset is ideal for this family of approaches.
You can find more details about the Argoverse 2 Map Change Dataset in our NeurIPS 2021 Dataset Track paper titled “Trust, but Verify”.
To download, visit our downloads section.
Download Argoverse 2 Dataset and Get Started
Argoverse 2 is provided free of charge under the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International Public license. Argoverse code and APIs are provided under the MIT license. Before downloading, please view our full Terms of Use.
For all datasets, we recommend downloading the data according to these instructions to avoid having to manage and decompress numerous archive files.
Argoverse 2 Sensor Dataset
Because of the large file size of the Sensor dataset (1 TB), we recommend downloading it according to these instructions. However, we do offer direct links to the dataset below.
Argoverse 2 Map Change Dataset
Because of the large file size of the Map Change Dataset (1 TB), we recommend downloading it according to these instructions. However, we do offer direct links to the dataset below. This script can be used to decompress the files.
Argoverse 2 Motion Forecasting Dataset
The Motion Forecasting Dataset can be directly downloaded according to these instructions, or you can download the archives below which total 58 GB in file size.
Update: We have released the test annotations to the community since we are moving away from hosted servers.
Argoverse 2 Lidar Dataset
Because of the large file size of the Lidar dataset (5 TB), please download it according to these instructions.